June 12, 2026
· 9 min readCRDTs: How Google Docs Survives Four People Typing at Once
Multi-user editing looks smooth, but underneath it's a distributed systems nightmare of shifting indexes. This post breaks down how CRDTs make merge conflicts mathematically impossible — character IDs, origin pointers, tombstones, and the YATA algorithm behind Yjs.
TL;DR
- Concurrent text edits break because indexes aren't stable — inserting one character shifts every position after it (the index shift problem).
- OT solves this with a central server that transforms operations; CRDTs solve it by redesigning the data structure so conflicts are mathematically impossible.
- CRDTs lean on three algebraic properties — commutativity, associativity, idempotence — so operations converge regardless of order or repetition.
- Real implementations like Yjs give every character a unique ID (
client + counter) plusorigin/originRightpointers, then break ties using the client ID. - Tombstones keep deleted characters in memory as stable anchors, enabling true local-first software with no merge conflicts.
Why collaborative editing is hard
You've probably been in a Google Doc with four other people typing at once. Your cursor doesn't jump. Their edits land where they're supposed to. Nothing breaks, nothing freezes. To you, it's smooth. To the computer, it's a terrifying distributed systems problem: how do you synchronize state across multiple machines, with unpredictable network latency, without locking the file?
To see why this is genuinely difficult, look at how text editing works under the hood.
Imagine a shared document with three letters: c a t. Two users, Alice and Bob, edit it at the exact same moment. Both see the same word.
- Alice wants
chat, so her client generates: inserthat index 1. - Bob wants
cats, so his client generates: insertsat index 3.
Both operations are calculated against the same snapshot — the word cat. Now the server applies them, and here's the problem. Even if it applies them one at a time in a perfectly clean order, the document still breaks.
Start: c a t
0 1 2
Alice: insert 'h' @1 c h a t ← every later char shifted right
0 1 2 3 't' moved from index 2 → index 3
Bob: insert 's' @3 c h a s t ← index 3 now sits in front of 't'Alice wanted chat. Bob wanted cats. They got chast.
The operations were correct. The order was correct. The problem is that index 3 in cat and index 3 in chat mean two different places. Indexes are relative to a snapshot, and the snapshot changed underneath Bob's hand.
It gets worse with deletes
If Alice deletes the a at index 1, the string becomes ct. If Bob's delayed insert s at index 3 arrives now, index 3 doesn't even exist anymore. The program either crashes or drops the letter in the wrong place.
The fundamental issue is always the same: indexes are not stable references.
The old way: locking and OT
Historically, systems solved this with a central authority.
Early collaborative tools used pessimistic locking — if Alice is typing, the document is locked and Bob's keyboard is disabled. Correct, but terrible UX.
Later, Google Docs popularized Operational Transformation (OT). The server intercepts every incoming operation, calculates how indexes have shifted based on other users' actions, mathematically transforms the operation, then broadcasts it back out.
OT works. But it's notoriously hard to implement, and it typically relies on a central server as the source of truth. Go offline for a while and merging your changes back cleanly becomes painful.
| Pessimistic Locking | Operational Transformation | CRDTs | |
|---|---|---|---|
| Concurrent edits | ❌ Blocked | ✅ Allowed | ✅ Allowed |
| Central server required | ✅ Yes | ✅ Usually | ❌ No |
| Offline editing | ❌ No | ⚠️ Difficult | ✅ Native |
| Implementation complexity | Low | High | Moderate |
| Merge guarantee | N/A | Server-transformed | Mathematical |
How CRDTs flip the problem
CRDTs approach this from a completely different angle. Instead of relying on a server to transform operations, they redesign the underlying data structure so conflicts are impossible to begin with.
To do that, CRDT merge logic satisfies three algebraic properties:
- Commutativity — order of operations doesn't matter:
a • b = b • a - Associativity — grouping doesn't matter:
(a • b) • c = a • (b • c) - Idempotence — applying the same operation twice changes nothing:
a • a = a
Put together, this means: no matter what order operations arrive in, and no matter how many times they're applied, the final state is always exactly the same. No coordinator required.
Stable IDs instead of indexes
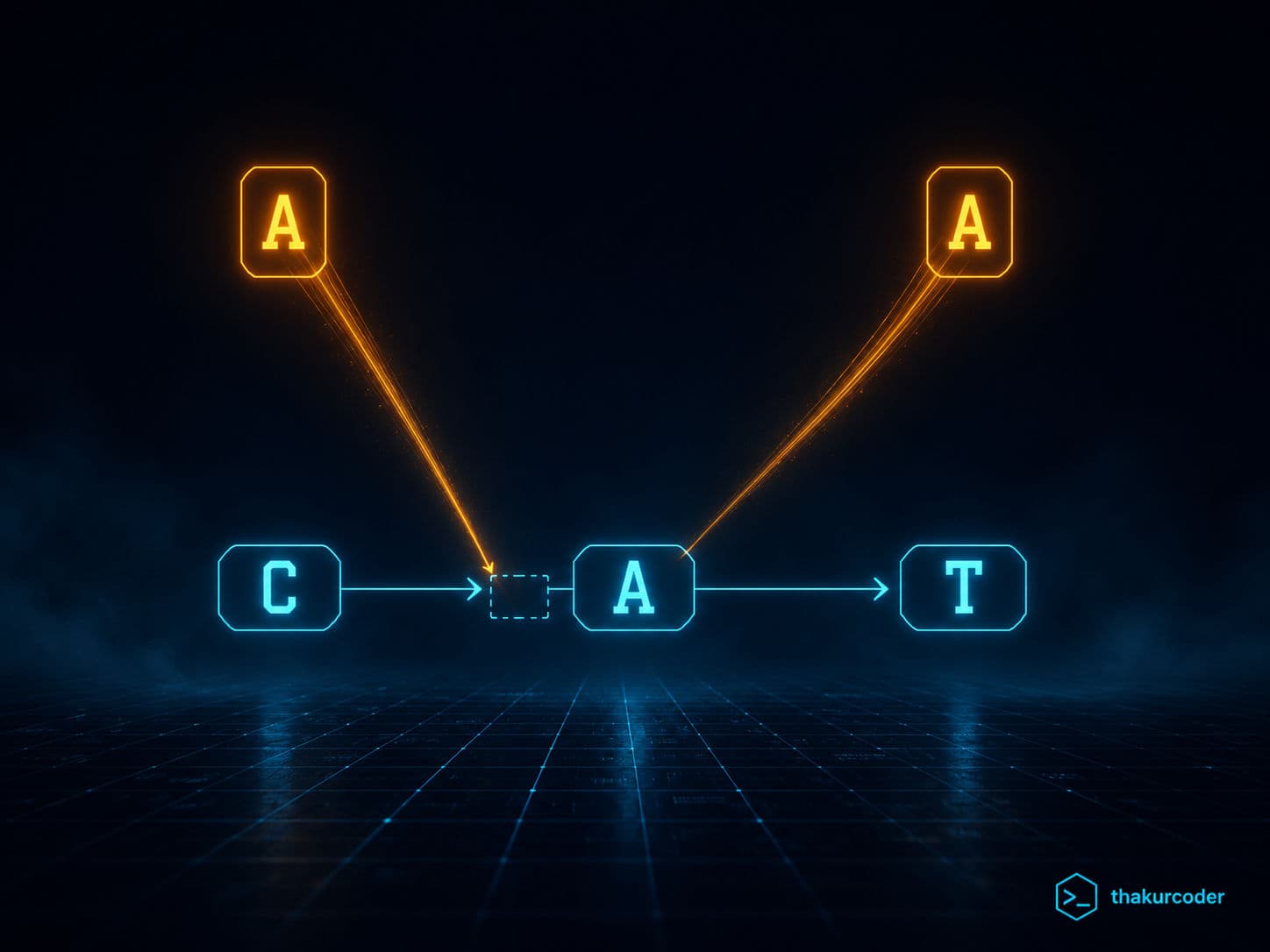
Real CRDTs like Yjs — the library behind many local-first editors — give every character a unique ID instead of a position. The ID is two simple things: which client typed it, and a counter that ticks up with every operation from that client.
Go back to C A T, all typed by Alice:
C → Alice:1
A → Alice:2
T → Alice:3The ID never changes. It's a permanent name for that character.
But IDs alone don't tell you what comes after what. So each character also remembers two neighbors at the moment it was typed: who was on its left (origin) and who was on its right (originRight).
C origin = ∅ originRight = ∅
A origin = C originRight = ∅
T origin = A originRight = ∅The document is now a tiny linked list: C → A → T.
💡 Tip:
originandoriginRightrecord the original neighbors at insertion time — they don't change as the document grows. That's exactly what makes them safe to reference across the network. Source: Yjs INTERNALS
Inserting with coordinates the network can't break
Alice wants to insert H between C and A. Her client doesn't record "index 1." It records:
H id = Alice:4 origin = C originRight = AThat's a coordinate the network can't corrupt. C and A are permanent names — even if other characters arrive between them later, "after C, before A" still makes sense.
The concurrent insert: where IDs earn their keep
Now imagine Bob, on a different machine at the exact same moment, also inserts H between C and A:
Alice broadcasts: H id = Alice:1* origin = C originRight = A
Bob broadcasts: H id = Bob:1 origin = C originRight = AWhen the messages reach each other's machines, both clients see two new characters trying to live in the same gap — same neighbors, same window. This is the moment OT needs a server for. CRDTs need only a rule.
The rule: when two characters share the same origin window, sort them by client ID.
Alphabetically, Alice comes before Bob. So on every machine, the order resolves identically:
C → [Alice's H] → [Bob's H] → A → TNot because a server picked it — because both machines applied the same sorting rule to the same data.
Because every character carries a permanent ID and remembers its origin window, network latency stops mattering. It doesn't matter if Alice's H arrives three days late. When it lands, the receiving client knows exactly what to do: find the gap between C and A and insert there. If Bob's H is already there, the client-ID rule decides the order — every time, on every machine.
This is the same idea YATA (the algorithm Yjs implements) uses: when peers concurrently insert at the same location, comparing client IDs alphanumerically guarantees identical ordering on all replicas regardless of arrival order. Source: Deep Dive into Y.js CRDTs
Deletions and the tombstone trick
There's one more hole to plug. If you delete a character, you free up its slot — and a delayed insert from another user might reference it as its origin or originRight. The reference would point to nothing.
CRDTs solve this with tombstones. When you press backspace, the character is not removed from the data structure. The CRDT just flips a flag:
T id = Alice:3 isDeleted = true ← UI hides it, data keeps itThe UI reads the flag and hides the character from the screen, but the structure keeps it. So if another user's delayed insert references that deleted character — say origin = A — even though A is gone from the screen, A is still in memory with its ID available as an anchor. The new character slots in next to the tombstone, and the document stays consistent.
⚠️ Warning: Tombstones never disappear on their own, so naïve CRDTs grow unbounded. Production libraries compress runs of characters and tombstones into compound blocks and store them in optimized structures (doubly-linked lists, B-trees) to keep memory in check.
The payoff: local-first software
Because CRDTs guarantee eventual consistency purely through math, they unlock a paradigm called local-first software.
A user can open an app on an airplane, work offline for 10 hours, make thousands of edits, and the moment they reconnect to Wi-Fi, their CRDT merges flawlessly with the rest of the team's changes. 🚀
- ✅ No merge conflicts
- ✅ No blocked UI
- ✅ No central source of truth
Under the hood, modern CRDT libraries heavily compress these IDs and tombstones so documents don't consume infinite RAM, organizing them into highly optimized structures like doubly-linked lists and B-trees.
When to reach for a CRDT (and when not to)
| Scenario | Good fit? |
|---|---|
| Real-time collaborative editor (docs, whiteboards, design tools) | ✅ Strong |
| Offline-first / local-first apps that sync later | ✅ Strong |
| Peer-to-peer apps with no central server | ✅ Strong |
| Simple single-writer data, or strict server-authoritative state | ❌ Overkill |
| Workloads where unbounded metadata growth is unacceptable and you can't prune | ⚠️ Be careful |
Conclusion
When I first internalized CRDTs, the click moment was realizing the trick isn't a smarter merge algorithm — it's a smarter identity. The instant you stop describing a character by where it sits (index 3) and start describing it by what it is (Alice:4, between C and A), the entire class of index-shift bugs evaporates. The data structure does the reconciliation for you.
By changing the data type itself, we eliminate the need for a central coordinator. We move from a fragile system of shifting indexes to an immutable, mathematically sound timeline of events. If you want to feel it in your hands, start with Yjs — wire it into a Monaco or ProseMirror editor, open two browser tabs, cut the network on one, type in both, then reconnect. Watching them converge with zero conflicts is the fastest way to make the theory stick.
FAQ
What is a CRDT?
A Conflict-free Replicated Data Type is a data structure designed so that concurrent edits from multiple machines always merge to the same result — no central coordinator needed. It guarantees convergence through math, not locking.
How is a CRDT different from Operational Transformation (OT)?
OT keeps a server that transforms incoming operations to account for index shifts. CRDTs redesign the data structure itself so conflicts can't happen, which removes the need for a central authority and enables offline editing.
What is the index shift problem?
When two users edit the same text concurrently, their operations reference positions (indexes) calculated against the original snapshot. Applying one operation shifts every following character, so the second operation's index now points somewhere else — producing a corrupted result.
What are tombstones in a CRDT?
When you delete a character, the CRDT doesn't remove it from memory — it just flags it as deleted and hides it from the UI. The character's ID stays as a stable anchor so that delayed inserts referencing it still resolve correctly.
What is Yjs?
Yjs is a popular CRDT library that powers many local-first editors and collaboration tools. It implements the YATA algorithm and uses origin/originRight pointers plus per-client IDs to resolve concurrent inserts deterministically.
Do CRDTs need a server?
No. Convergence is guaranteed by the data structure, so peers can merge directly. A server is often used as a relay for convenience, but it isn't required as a source of truth like it is in OT.